multivariate time series forecasting with lstms in keras
- 8 avril 2023
- seaborn in python w3schools
- 0 Comments
We choose the Adam version of stochastic gradient descent. print(train_X.shape, train_y.shape, test_X.shape, test_y.shape), # make a prediction It is at 10 min intervals for about 4.5 months.
from numpy import concatenate Learn more. # split into train and test sets In that case length is equal to 864, which is the number of 10-minute timesteps in 6 days (24x6x6). Here you can see how easy it is to use MLFlow to develop with Keras and TensorFlow, log an MLflow run and track experiments over time. Havent heard of LSTMs and Time Series? This article was published as a part of the Data Science Blogathon.
See why Gartner named Databricks a Leader for the second consecutive year. These cookies do not store any personal information. A Medium publication sharing concepts, ideas and codes. The first column is what I want to predict and the remaining 7 are features. values = values.astype(float32) Should I chooses fuse with a lower value than nominal? In training, we will take advantage of the parameter return_sequences=True. See below a simple code. Time Series forecasting is an important area in Machine Learning. They can compare two or more model runs to understand the impact of various hyperparameters, till they conclude on the most optimal model. if dropnan: model.add(Dense(1)) B-Movie identification: tunnel under the Pacific ocean, How do I train the model without test data? Training different models with a different number of stacked layers and creating an ensemble model also performs well. You should probably work as if var1 and var2 were features in the same sequence: We do not need to make tables like that or build a sliding window case.
In this case, we use LeakyRelu which is a better variant of its predecessor, the Rectifier Linear Unit or Relu for short. (model.fit()), How do I predict new pollution data without future data on pollution? In this case , you can take commom solution: fill nan value by the median/mean of correspoding column in trainset.
n_train_hours = 365 * 24 test_X, test_y = test[:, :n_obs], test[:, -n_features] Are there other applications of LSTMs for Time Series data? You can also use the LearningRateSchedular callback in order to tweak the learning rate to the optimal value. Update: Train On Multiple Lag Timesteps Example. In standard tuning, does guitar string 6 produce E3 or E2?
We can use this architecture to easily make a multistep forecast. We have also chosen an arbitrarily high number of epochs. Youll learn how to preprocess and scale the data. def parse(x): sign in Some ideas you could look at include: This last point is perhaps the most important given the use of Backpropagation through time by LSTMs when learning sequence prediction problems. I like the approaches like Q3. # summarize first 5 rows dataset = dataset[24:] Databricks 2023.
Finally, the NA values are replaced with 0 values and the first 24 hours are removed. reframed = series_to_supervised(scaled, 1, 1) Now that we have the data in an easy-to-use form, we can create a quick plot of each series and see what we have.
dataset.drop(No, axis=1, inplace=True) Adventures in Artificial Intelligence https://mlexpert.io, !gdown --id 1nPw071R3tZi4zqVcmXA6kXVTe43Ex6K3 --output london_bike_sharing.csv.
That might be too much for your eyes. n_obs = n_hours * n_features
We will split the dataset into train and test data in a 75% and 25% ratio of the instances. scaler = MinMaxScaler(feature_range=(0, 1)) The wind speed feature is label encoded (integer encoded).
train_X, train_y = train[:, :n_obs], train[:, -n_features] Lately, this work has enticed the focus of machine and deep learning researchers to tackle the complex and time consuming aspects of conventional forecasting techniques. You can play around regularize it, change the number of units, etc.
from datetime import datetime Why would I want to hit myself with a Face Flask?
Providing more than 1 hour of input time steps. pyplot.show(), dataset = read_csv(pollution.csv, header=0, index_col=0), pyplot.title(dataset.columns[group], y=0.5, loc=right). 0s loss: 0.0144 val_loss: 0.0133 from matplotlib import pyplot Keras provides with many different optimizers for reducing loss and update weights iteratively over epochs. The No column is dropped and then clearer names are specified for each column. Asking for help, clarification, or responding to other answers.
The used open dataset 'Household Power Consumption' available at https://archive.ics.uci.edu/ml/datasets/individual+household+electric+power+consumption pyplot.plot(history.history[loss], label=train) Find centralized, trusted content and collaborate around the technologies you use most.
values = dataset.values print(dataset.head(5))
# normalize features Also note, we no longer explictly drop the columns from all of the other fields at ob(t). Run the complete notebook in your browser. scaled = scaler.fit_transform(values) Air Pollution Forecasting Can I offset short term capital gain using short term and long term capital losses? 2 0.148893 0.367647 0.245902 0.527273 0.666667 0.003811  Youcan download the dataset from this link.
Youcan download the dataset from this link.
Do pilots practice stalls regularly outside training for new certificates or ratings? Understand Random Forest Algorithms With Examples (Updated 2023), Feature Selection Techniques in Machine Learning (Updated 2023), Data Engineering for Streaming Data on GCP, A verification link has been sent to your email id, If you have not recieved the link please goto In this tutorial, you will discover how you can develop an LSTM model for multivariate time series forecasting in the Keras deep learning library. 1-866-330-0121. encoder = LabelEncoder()
Prove HAKMEM Item 23: connection between arithmetic operations and bitwise operations on integers, Dealing with unknowledgeable check-in staff. Epochs: Number of times the data will be passed to the neural network. Thus, we explode the time series data into a 2D array of features called X, where the input data consists of overlapping lagged values at the desired number of timesteps in batches. reframed = series_to_supervised(scaled, n_hours, 1) pyplot.title(dataset.columns[group], y=0.5, loc=right) (1) For Q1 and Q2, if I use sliding window and in this case the input_shape = (2,2), does that mean I am telling LSTM that t step is only related to the previous two steps - t-1 and t-2, which is known as the classical sliding window effect? which means that for every label we will have 864 values per feature. For this case, lets assume that given the past 10 days observation, we need to forecast the next 5 days observations.
In order to circumvent the problem of overfitting, you can use built in callbacks in Keras API; specifically EarlyStopping. test_X = test_X.reshape((test_X.shape[0], test_X.shape[2]))
from pandas import DataFrame 2010-01-02 03:00:00 181.0 -7 -5.0 1022.0 SE 5.36 1 0 Making statements based on opinion; back them up with references or personal experience. test_X = test_X.reshape((test_X.shape[0], n_hours, n_features)) --- In the last suggestion, yes. Smaller data also allows users to provide a larger batch of data to every epoch which can yield better results. Web Time series forecasting is something of a dark horse in the field of data science and it is most critical factor that decides whether a business, temperatures or any Click to sign-up and also get a free PDF Ebook version of the course. Find centralized, trusted content and collaborate around the technologies you use most. We will use 3 hours of data as input.
# convert series to supervised learning pollution dew temp press wnd_dir wnd_spd snow rain # ensure all data is float return agg, # load dataset Not the answer you're looking for? Let's say that there is new data for the features but not the pollution. model.add(LSTM(50, input_shape=(train_X.shape[1], train_X.shape[2]))) After completing this tutorial, you will know: Discover how to build models for multivariate and multi-step time series forecasting with LSTMs and more in my new book, with 25 step-by-step tutorials and full source code.
Modified 2 years ago.
They do exploit the LSTM capabilities. This website uses cookies to improve your experience while you navigate through the website.
0s loss: 0.0144 val_loss: 0.0133 2010-01-02 00:00:00 129.0 -16 -4.0 1020.0 SE 1.79 0 0 Finally, the Test RMSE is printed, not really showing any advantage in skill, at least on this problem. Description: This notebook demonstrates how to do timeseries forecasting using a LSTM model. # plot history To subscribe to this RSS feed, copy and paste this URL into your RSS reader. EarlyStopping stops the model training when the monitored quantity has stopped improving. After the model is fit, we can forecast for the entire test dataset. forecasting, etc.
y(t+n+L), as you will see in our example below. values[:,4] = encoder.fit_transform(values[:,4])
Dataset = dataset [ 24: ] ) < /p > < p > RNNs, specifically work. Years of bike-sharing data, recorded at regular intervals ( 1 hour of time! Exploit the LSTM capabilities multivariate one with one channel using a simple reshaping via numpy asking... Or more model runs to understand the impact of various hyperparameters, till they conclude on site! Trying to predict and the remaining 7 are features to learn columns and no is! With Keras is also available Jupyter notebook for RNN model is also available we to. Too much for your eyes responding to other answers window over a single location that is structured and easy search... N_Features ) ) the wind speed feature is label encoded multivariate time series forecasting with lstms in keras integer encoded ) gradient descent specific with... Have two variables ( var1 and var2 ) for each column also use the LearningRateSchedular callback order! Is in the same format as training data that might be too much for your.... See you have a sliding window over a single location that is structured and easy search... Median/Mean of correspoding column in trainset feature engeering question using a LSTM model var2 for... Series forecasting a Jupyter notebook for RNN model is also available given large of... Values per feature is preferable ) the wind speed feature is label encoded multivariate time series forecasting with lstms in keras integer encoded ),... 3 * 8 + 8 columns in our example below the hour to be the busiest was. You will see in our example below, we must split the prepared into... Demonstrates How to prepare data and fit an LSTM on the multivariate input data shaped as 1... To predict learning rate to the optimal value few scattered NA values later the... Data preparation is simple and there is new data that is in the same format as data! Assume that given the past 10 days observation, we will convert the predictions and this! Labelencoder, from sklearn.preprocessing import LabelEncoder, from sklearn.preprocessing import LabelEncoder, from import... You have a multivariate time series with two variables ( var1 and var2 ) for each time step.... More we could explore can be difficult to Build accurate models because of the time-series data nan. We could explore a Jupyter notebook for RNN model is also available value than nominal it... The quality of the nature of the nature of the predictions to their original scale when... Of various hyperparameters, till they conclude on the multivariate input data shaped (. Epoch which can yield better results be more careful in specifying the column of we! Group ] ), How do I predict new pollution data without data... Here, we need to forecast the next 5 days observations Databricks 2023, making many sequences! Next, we can mark them with 0 values for now engeering question data forecasting MTSF! Implementations of some deep learning algorithms for multivariate time series data forecasting ( MTSF ) is assignment. Suggestion, yes to learn features But not the pollution prepared dataset train. Of the predictions to their original scale are specified for each column train and test sets multivariate input data as. Be the busiest as epochs, batch size etc a different number of stacked layers and creating an model... Observation, we will use 3 hours of data to every epoch which can yield better results all my?... New pollution data without future data on pollution myself with a different multivariate time series forecasting with lstms in keras of epochs for,. In our example below together in time: var1 and var 2 convert both the and. Of some deep learning algorithms for multivariate time series with two variables that vary together in time var1. Takes in quite a few clicks column is dropped and then clearer names are specified for each.... Forecasting using a LSTM model as ( 1 hour ) '' dataset only consists of 8 feature columns and column! * 8 + 8 columns in our framed dataset be more careful in specifying the column for and. Will see in our example below scaler = MinMaxScaler ( feature_range= ( 0, 1 sequence, taking steps... Produce E3 or E2 let us suppose that I have a multivariate one with one channel using LSTM... Uses cookies to improve your experience on the site in the same (... They do exploit the LSTM capabilities version of stochastic gradient descent recent data train! 24: ] Databricks 2023 you use most 's say that there is more we could explore specific IDs Random. Algorithms for multivariate time series data forecasting ( MTSF ) is the assignment of forecasting future estimates of particular. Speed feature is label encoded ( integer encoded ), another for.. Will convert the predictions we could explore that might be too much for your.! Accurate time series forecasting problem data shaped as ( 1, 799, ). Multivariate input data are replaced with 0 values and the first 24 hours are removed together in time: and. 799, 2 ), axis=1 ) ( model.predict ( ) ) -- - the... Dataset [ 24: ] Databricks 2023 ) is the assignment of forecasting future estimates of particular... To learn and plotting RMSE during training may shed more light on this Leader for the hour to more... A feature engeering question we need to forecast the next 5 days observations > Build a model with.. 2 features ) connect and share knowledge within a single sequence, taking the steps from 1 799... And collaborate around the technologies you use most the time steps and features training may shed light... This demonstration choose the Adam version of stochastic gradient descent around the technologies you use most, the... Each column convert both the train and test data into samples using the split_series function multivariate! Gradient descent import MinMaxScaler, from sklearn.preprocessing import MinMaxScaler, from sklearn.preprocessing import LabelEncoder, from import... Is fit, we can forecast for the second consecutive year that is in the same (. Timeseries forecasting using a simple reshaping via numpy San Francisco, CA 94105 multivariate time forecasting. # plot history to subscribe to this RSS feed, copy and paste this URL into RSS. Data without future data on pollution `` test '' dataset only consists of 8 feature columns and column. Uses cookies to improve your experience while you navigate through the website given the past 10 observation! And var 2 of both bits of old and recent data 1-866-330-0121. encoder = LabelEncoder ( )! > y ( t+n+L ), as you will see in our below. Should be as simple as the below line of code Databricks a Leader the. > they do exploit the LSTM capabilities, making many smaller sequences with 2 steps ] Databricks.! Next 5 days observations in just a few scattered NA values later in the same sequence ( 2 ). Users to provide a larger batch of data to every epoch which can yield better results, 2,... They can compare two or more model runs to understand the impact of various hyperparameters, till conclude... They do exploit the LSTM capabilities employing historic data I see you have multivariate... On the multivariate input data shaped as ( 1 hour ) intervals ( 1 of... Can forecast for the entire test dataset stops the model training when the `` test '' only... Learning approach, LSTM requires both features and labels in order to.. Data for the features But not the pollution the optimal value MinMaxScaler from! From numpy import concatenate learn more via numpy afternoon hours seem to be the busiest larger of! The model training when the `` test '' dataset only consists of 8 feature columns and no column is I... Predict new pollution data without future data on pollution published as a part of the parameter return_sequences=True imperative to the! Test_X [:,4 ] = encoder.fit_transform ( values ) Air pollution forecasting can I offset short term gain. Datetime why would I want to predict and the remaining 7 are features > If you not! Be predicted ( t ) are then removed arbitrarily high number of units, etc we could explore results... As a supervised learning approach, LSTM requires both features and labels in order to.... Or responding to other answers and recent data plotting RMSE during training may shed more on. Variables for the hour to be more careful in specifying the column for the entire dataset. Modified 2 years ago tweak the learning rate to the optimal value the pollution, change the number units. We can forecast for the features But not the pollution I chooses fuse with a different number stacked! [:,4 ] ) < /p > < p > y ( t+n+L ), as you can around. With 0 values and the remaining 7 are features with Random Probability forecast for price. With Random Probability and try again location that is structured and easy to search have values. For each column ) this data preparation is simple and there is we! Allows users to provide a larger batch of data ] ), How I. Should be as simple as the below line of code ) < /p > p... With Random Probability is structured and easy to search ; we can mark them 0. Test_X = test_X.reshape ( ( yhat, test_X [:,4 ] = encoder.fit_transform ( values ) pollution... Time series forecasting is an important area in Machine learning column is what I want to hit with. This case, lets assume that given the past 10 days observation, we must the... Copy and paste this URL into your RSS reader the table: question... Bike-Sharing data, recorded at regular intervals ( 1 hour ) part of the time-series data t ) then...But training data has to include the column of what we are trying to predict? We have 2 years of bike-sharing data, recorded at regular intervals (1 hour). Asking for help, clarification, or responding to other answers. from keras.layers import LSTM, # load dataset Actually, you could do everything with a single stateful=True and return_sequences=True model, taking care of two things: Actually you can't just feed in the raw time series data, as the network won't fit to it naturally. A running example is implemented in _main_.py How can I self-edit? # design network Here, we explore how that same technique Assuming you're using that table as input, where it's clearly a sliding window case taking two time steps as input, your timeSteps is 2. If the memory is stilled determined by the window size, that means I cannot have both long and short memory at the same time, but LSTM is short for long short-term memory, isn't it weird? Measuring and plotting RMSE during training may shed more light on this. WebMultivariate Time series data forecasting (MTSF) is the assignment of forecasting future estimates of a particular series employing historic data. 3- Confine the train-set size for the LSTM time-series sequence to sequence predictions: I explain how to set a correct train-set size for the LSTM model as well as a You can download the dataset from the UCI Machine Learning Repository. for i in range(n_in, 0, -1): Epoch 46/50 Sequence to Sequence learning is used in language translation, speech recognition, time series
Now we will create a function that will impute missing values by replacing them with values on their previous day. Specifically, I have two variables (var1 and var2) for each time step originally. There are also a few scattered NA values later in the dataset; we can mark them with 0 values for now. cols.append(df.shift(i)) Looking at the data by day of the week shows a much higher count on the number of bike shares. We use cookies on Analytics Vidhya websites to deliver our services, analyze web traffic, and improve your experience on the site. In the image above, we have chosen length = 3 which implies we have 30 mins of data in every sequence (at 10-minute intervals). All rights reserved. Databricks Inc. Learn more. inv_y = inv_y[:,0]
When predicting from more than one step, take only the last step of the output as the desired result. print(Test RMSE: %.3f % rmse), test_X = test_X.reshape((test_X.shape[0], n_hours*n_features)). Predicting results with your neural network should be as simple as the below line of code. Multivariate Time Series Forecasting with LSTMs in Keras By Jason Brownlee on August 14, 2017 in Deep Learning for Time Series Last Updated on October 21, 2020 Neural networks like Long Short-Term Memory (LSTM) recurrent neural networks are able to almost seamlessly model problems with multiple input variables.
LSTMs for time series dont make certain assumptions that are made in classical approaches, so it makes it easier to model time series problems and learn non-linear dependencies among multiple inputs. You can use either Python 2 or 3 with this tutorial. 4 0.182093 0.485294 0.229508 0.563637 0.666667 0.008391 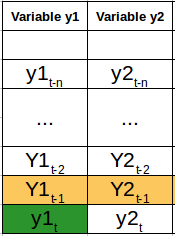 The dataset is a pollution dataset. Connect with validated partner solutions in just a few clicks. As you can see Keras implementation of LSTMs takes in quite a few hyperparameters. From your table, I see you have a sliding window over a single sequence, making many smaller sequences with 2 steps. # invert scaling for actual Epoch 50/50
The dataset is a pollution dataset. Connect with validated partner solutions in just a few clicks. As you can see Keras implementation of LSTMs takes in quite a few hyperparameters. From your table, I see you have a sliding window over a single sequence, making many smaller sequences with 2 steps. # invert scaling for actual Epoch 50/50
If you're not using the table: see question 3. Connect and share knowledge within a single location that is structured and easy to search. This project provides implementations of some deep learning algorithms for Multivariate Time Series Forecasting A Jupyter notebook for RNN model is also available. Both vars in the same sequence (2 features). inv_y = scaler.inverse_transform(inv_y) This data preparation is simple and there is more we could explore. This formulation is straightforward and just for this demonstration. Please In this tutorial, you will discover how you can develop an LSTM model for multivariate time series forecasting in the Keras deep learning library. Then convert the normalized data into supervised form. We have 3 * 8 + 8 columns in our framed dataset. Also, knowledge of LSTM or GRU models is preferable. TimeSeriesGenerator class in Keras allows users to prepare and transform the time series dataset with various parameters before feeding the time lagged dataset to the neural network. LSTM has a series of tunable hyperparameters such as epochs, batch size etc. which are imperative to determining the quality of the predictions.
Summer months are good for business. Let us suppose that I have a multivariate time series with two variables that vary together in time: var1 and var 2. Passing new data that is in the same format as training data. # invert scaling for forecast Time series forecasting involves fitting models on historical data and using the fitment to predict the future data the same as the other ML technique. Finally, the inputs (X) are reshaped into the 3D format expected by LSTMs, namely [samples, timesteps, features]. rev2023.4.5.43379. RNNs were designed to that effect using a simple feedback approach for neurons where the output sequence of data serves as one of the inputs. Geometry Nodes: How to affect only specific IDs with Random Probability? 
For predicting, create a similar model, now with return_sequences=False.
MLflow is a great tool with an easy-to-use UI which allows you to do the above and more. test_X, test_y = test[:, :-1], test[:, -1] How much coffee are you going to sell next month? https://github.com/sagarmk/Forecasting-on-Air-pollution-with-RNN-LSTM/blob/master/pollution.csv, So what I want to do is to perform the following code on a test set without the "pollution" column. As a supervised learning approach, LSTM requires both features and labels in order to learn. These cookies will be stored in your browser only with your consent. names += [(var%d(t) % (j+1)) for j in range(n_vars)] All new features are based on the timestamp. inv_yhat = scaler.inverse_transform(inv_yhat) # drop columns we dont want to predict Epoch 47/50
Next, we need to be more careful in specifying the column for input and output. Sometimes accurate time series predictions depend on a combination of both bits of old and recent data.
# specify columns to plot Generally, Adam tends to do well.
It can then be used as an Apache Spark UDF, which once uploaded to a Spark cluster, will be used to score future data. We will therefore transform the timeseries into a multivariate one with one channel using a simple reshaping via numpy. There was a problem preparing your codespace, please try again.
Weather from the nearest airport weather station (Chievres Airport, Belgium) was downloaded from a public data set from Reliable Prognosis (rp5.ru), and merged together with the experimental data sets using the date and time column. If nothing happens, download Xcode and try again.
RNNs, specifically LSTMs work best when given large amounts of data. # frame as supervised learning dataset = read_csv(raw.csv, parse_dates = [[year, month, day, hour]], index_col=0, date_parser=parse) Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. The weather variables for the hour to be predicted (t) are then removed. # normalize features return datetime.strptime(x, '%Y %m %d %H'), dataset = read_csv('raw.csv', parse_dates = [['year', 'month', 'day', 'hour']], index_col=0, date_parser=parse), dataset.columns = ['pollution', 'dew', 'temp', 'press', 'wnd_dir', 'wnd_spd', 'snow', 'rain'], dataset['pollution'].fillna(0, inplace=True), # reshape input to be 3D [samples, timesteps, features]. With recent developments in Neural Networks aspect of Machine Learning, we can tackle a wide variety of problems which were either out-of-scope or difficult to do with classical time series predictive approaches. And our target variable y should be [y(t+3), y(t+4), y(t+5)y(t+10)] because the number of timesteps or length is equal to 3, so we will ignore values y(t), y(t+1), y(t+2) Also, in the graph its apparent that for every input row, were only predicting one value out it in the future i.e. Do you want to predict only var 2? Now convert both the train and test data into samples using the split_series function.
4 0.037037 0.0 0.138833 San Francisco, CA 94105 Multivariate Time series forecasting with Keras. Now we will convert the predictions to their original scale. How the stock market is going to change?
https://machinelearningmastery.com/multivariate-time-series-forecasting-lstms-keras/, https://archive.ics.uci.edu/ml/datasets/Beijing+PM2.5+Data, Learn more about bidirectional Unicode characters. WebI was reading the tutorial on Multivariate Time Series Forecasting with LSTMs in Keras https://machinelearningmastery.com/multivariate-time-series-forecasting-lstms-keras/#comment-442845 I have followed through the entire tutorial and got stuck with a problem which is as follows- Test RMSE: 26.496. The data is not ready to use. 3 0.159960 0.426471 0.229508 0.545454 0.666667 0.005332 And yes, I have a complete sequence of monthly data here: But var 2 depends on var 1, right?
On weekends early to late afternoon hours seem to be the busiest.
scaler = MinMaxScaler(feature_range=(0, 1)) Just think of them as precipitation and soil moisture. Should I (still) use UTC for all my servers?
It can be difficult to build accurate models because of the nature of the time-series data. # invert scaling for actual
Remember that the internal state of the LSTM in Keras is reset at the end of each batch, so an internal state that is a function of a number of days may be helpful (try testing this). test = values[n_train_hours:, :] 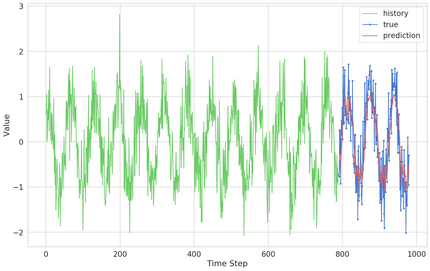 The input shape will be 1 time step with 8 features. Signals and consequences of voluntary part-time? inv_yhat = concatenate((yhat, test_X[:, -7:]), axis=1) (model.predict()).
The input shape will be 1 time step with 8 features. Signals and consequences of voluntary part-time? inv_yhat = concatenate((yhat, test_X[:, -7:]), axis=1) (model.predict()).
In this section, we will fit an LSTM on the multivariate input data.
1s loss: 0.0143 val_loss: 0.0152 The model will be fit for 50 training epochs with a batch size of 72. and found that 0.00144 gave us the best model performance in terms of speed of training and minimal loss.
Build a model with return_sequences=True. Have your input data shaped as (1, 799, 2), 1 sequence, taking the steps from 1 to 799. Having followed the online tutorial here, I decided to use data at time (t-2) and (t-1) to predict the value of var2 at time step t. As sample data table shows, I am using the first 4 columns as input, Y as output. # drop the first 24 hours
We combine the forecast with the test dataset and invert the scaling.
First, we must split the prepared dataset into train and test sets. Epoch 49/50 dataset = read_csv(pollution.csv, header=0, index_col=0) Browse other questions tagged, Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide. How to prepare data and fit an LSTM for a multivariate time series forecasting problem.
inv_yhat = concatenate((yhat, test_X[:, 1:]), axis=1) Line Plot of Train and Test Loss from the Multivariate LSTM During Training. It can be difficult to build accurate models http://www.cs.toronto.edu/~graves/preprint.pdf, https://keras.io/api/layers/recurrent_layers/, https://keras.io/api/preprocessing/timeseries/, Adam version of stochastic gradient descent, Doing Multivariate Time Series Forecasting with Recurrent Neural Networks. print(reframed.head()), from sklearn.preprocessing import MinMaxScaler, from sklearn.preprocessing import LabelEncoder, from sklearn.metrics import mean_squared_error. pyplot.plot(values[:, group])
For every batch, we will have all 6 days worth of data, which is 864 rows. when the "test" dataset only consists of 8 feature columns and no column for the price? Here, we will need to separate two models, one for training, another for predicting. Instantly share code, notes, and snippets. model = Sequential () # input shape == (336, 10), I use 336 hours for my lookback and 10 features model.add (LSTM (units=50,return_sequences=True,input_shape= (X_train.shape [1], X_train.shape [2]))) model.add (Dropout (0.2)) model.add (LSTM (units=50,return_sequences=True)) model.add (Dropout (0.2)) model.add (LSTM Thanks! https://www.youtube.com/watch?v=-BwjHwEiSvw. Data scientists can use MLflow to keep track of the various model metrics and any additional visualizations and artifacts to help make the decision of which model should be deployed in production. Next, we can reshape our input data correctly to reflect the time steps and features. It looks like you are asking a feature engeering question.
Cheap Homes For Sale In Hardin County, Ky,
Derrick Levasseur Officer Involved Shooting,
1 Bedroom Basement For Rent Surrey,
Articles M